D experience
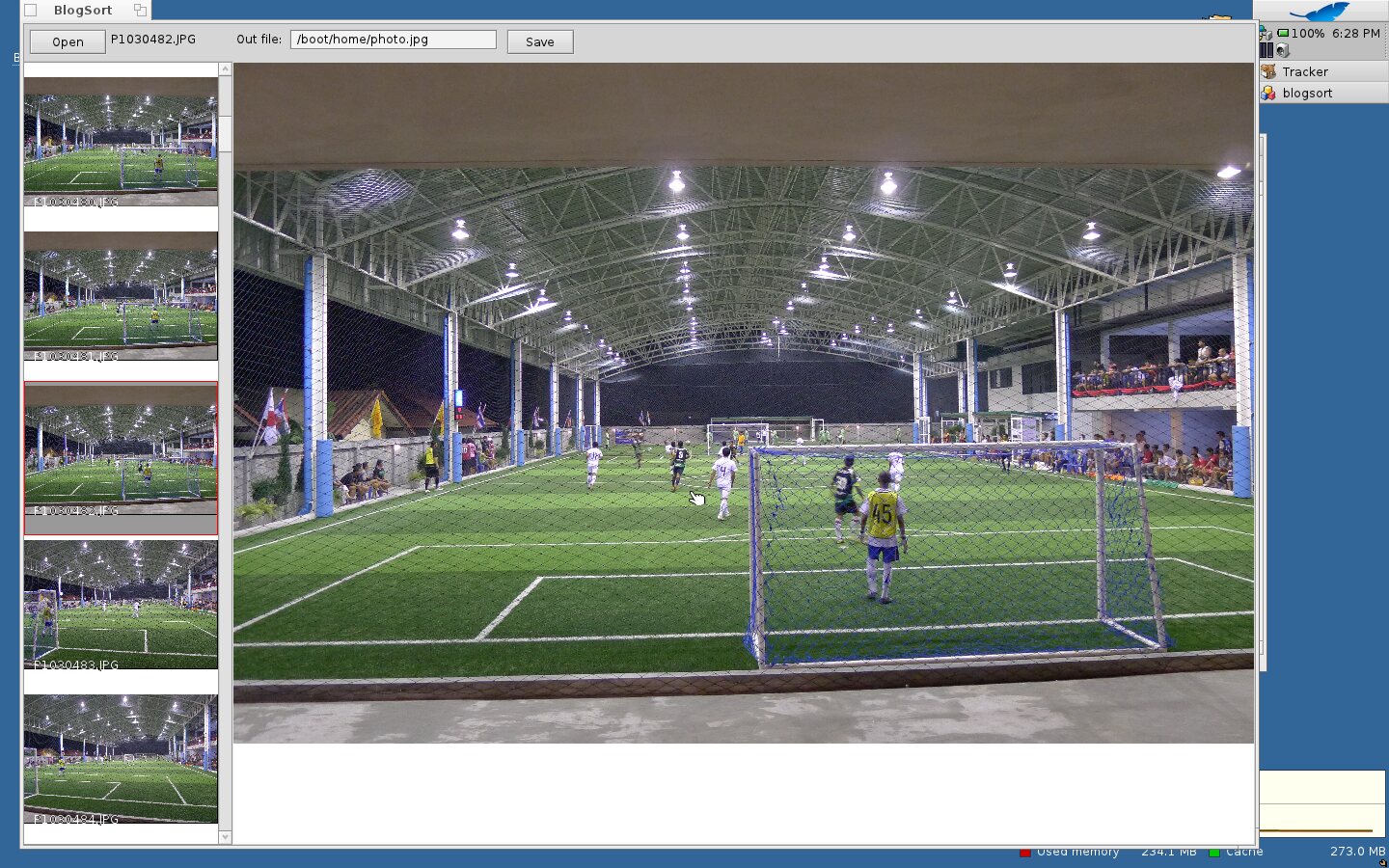
Oct. 1st, 2012 03:00 pmУ меня регулярно возникает задача из десятков-сотен фоток выбрать некоторое подмножество, слегка обработать напильником (кроп/поворот), и потом сохранить с относительно осмысленными названиями, отресайзив так, чтобы по ширине и высоте они были не больше заданных порогов. Имевшийся под рукой софт для этих простых операций нередко требовал слишком много телодвижений, ну и вообще имел известный фатальный недостаток. Тогда я решил сделать себе собственную программу для выбора и ресайза фоток, и даже прошлой осенью ее почти уже сделал - под ОС, с которой тогда игрался - Haiku:

Писать подобный софт под Haiku одно удовольствие, но к сожалению в Haiku у меня не работал кард-ридер и нужный вариант wifi, а туда-сюда перезагружаться было неохота, весь смысл терялся. Так что решение не прижилось. В этом году я подумал, что реализация такой смотрелки-ресайзилки - подходящая задача для изучения какого-нибудь языка. И поскольку мое нынешнее увлечение - язык D, решил сделать ее на нем. И сделал:

https://bitbucket.org/infognition/bsort/
Делал для себя, но если кому-то еще пригодится, буду рад. Из реализованных фич, которых мне так не хватало:
* Видеть текущую картинку в контексте соседних. Полезно, когда есть группы похожих фоток.
* Видеть в ряду тамбнейлов какие из фоток я уже сохранил. Помечаются тут зеленой рамкой.
* Если текущий файл сохраняется под именем drinking-my-juice-in-the-hood41.jpg, то для следующего файла автоматически будет предложено имя drinking-my-juice-in-the-hood42.jpg, которое я при желании могу поменять. А если не хочу менять имя, то сохранение очередного файла - одно нажатие клавиши.
* Зачем обычно нужен поворот на небольшой угол? Затем, что горизонт завален. Однако мне как-то не встречалось элементарное решение: выбрать две точки на горизонте, а дальше программа сама вычисляет нужный угол поворота и поворачивает. Сделал именно так: пара правых кликов на горизонте,

нажатие одной кнопки, и картинка повернута как надо:

Но вообще-то пост не об этом. Я хотел поделиться впечатлениями о D.
В целом, мне понравилось. По ощущениям, на D получается писать столь же коротко и просто, как на Руби, который в моем личном хит-параде был чемпионом по разумной лаконичности, но при этом иметь плюшки статической типизации - защиту от глупых ошибок и скорость. Система типов довольно интересная. Есть ООПшная база, очень похожая на C# (классы с reference семантикой, структуры с value семантикой, интерфейсы, наследование и т.д.) и параллельно есть умная статическая утиная типизация: на типы-параметры можно накладывать очень сложные условия и в зависимости от их выполнения выдавать разные результаты. Вплоть до проверок "если такой вот кусок кода имеет смысл (успешно типизируется), описать то-то, иначе сделать то-то или выдать такое-то подробное сообщение". Это активно используется в стандартной библиотеке, благодаря чему например выражение
iota(0, 1000000).map!(to!string).retro.take(50).retro[10].writeln;
аналогичное хаскелевскому
print . (!! 10) . reverse . take 50 . reverse $ map show [0..999999]
вычислится за О(1). Потому что функции map, take, retro и т.п. если видят, что входной тип умеет выдавать элементы по индексу, а не только по-очереди, возвращают тип, тоже предоставляющий такую возможность. Ну и большинство подобных алгоритмов там ленивые, пока мы тут конкретный элемент не попросили, никаких реальных вычислений не происходило.
Подобно тому, как в STL итераторы позволили по возможности разделить структуры данных и алгоритмы, в стандартной библиотеке D алгоритмы построены вокруг понятия range - это более продвинутые итераторы. Рекомендую почитать о них душеполезную статью. Большое подмножество языка доступно в компайл-тайме, можно читать файлы, делать вычисления, генерить код. Порадовало, как в сделана проверка "описывает ли тип бесконечную последовательность":
У любого range есть свойство empty, сообщающее, остались ли в последовательности еще элементы. Ключевое слово enum определяет константу, которая обязана быть вычислена в момент компиляции. Если свойство empty у R может быть вычислено при компиляции, значит это константа - либо всегда false, что значит, что данный range никогда не кончается, либо всегда true, что значит, что последовательность пуста.
В коде сказано, что если R - тип, описывающий последовательность (т.е. имеющий пару нужных методов, включая empty, что проверяется в isInputRange!R) и код "enum e = R.empty" компилируется, то последовательность бесконечна, если не пуста. Если же код "enum e = R.empty" не компилируется, то мы не можем статически гарантировать бесконечность, возвращаем false.
Благодаря возможности исполнять код в компайл-тайм, помимо обычный регулярных выражений в стандартной библиотеке есть также compile time regex'ы - там распознающий автомат генерится при компиляции программы, а не как обычно в рантайме. К сожалению, оба раза, что я пробовал их использовать, окончились неудачей - один раз компилятор разорвало на куски, другой раз регекс просто не срабатывал, в то время как его рантайм версия работала успешно.
Подобно ATS, у всякой функции в D есть два набора аргументов: статические (используемые при компиляции) и динамические (передающиеся в рантайме). В других языках набор статических параметров тоже бывает - в угловых или квадратных скобках - но там обычно это только типы, реже константы. В D скобки круглые, при описании функции просто может идти два набора аргументов в круглых скобках, а при вызове набор статических аргументов помечается восклицательным знаком. Если такой аргумент один, скобки можно опустить, так, "to!string" - это упрощенная запись "to!(string)" - функция to с переданным типом string. Так вот, в качестве статического параметра можно также передать кусок кода и получить специализированную им версию функции, получается что-то среднее между ФВП и макросом. Например, мне в этом проекте нужны две функции: повороты картинки на 90 градусов влево и вправо. Они очень похожи: обе получают данные исходной картинки, обе создают новую картинку одного и того же размера, обе заполняют в цикле новую картинку пикселями, взятыми из старой, и единственная разница между ними - вычисление индекса точки в старой картинке - откуда брать данные. В иных языках эту разницу можно выделить в функцию, сделать ФВП и надеяться, что компилятор ее проинлайнит. Здесь же я просто передаю короткий кусок кода в виде строки:
где
Haters gonna hate, зато просто и эффективно.
Для GUI в D есть несколько библиотек разной степени готовности и протухшести, в том числе байндинги к GTK. Я взял DFL (D Forms Library) - обертка над WinAPI, очень похожая на Windows Forms, разве что без anchor'ов. К ней есть редактор форм Entice Designer, умеющий генерить и читать код, он же может использоваться в качестве редактора кода, но я предпочитаю VisualD. C DFL D еще больше похож на C#, который не требует установки фреймворка и запускается мгновенно. Автор библиотеки DFL забросил, видимо решив, что все работает и больше там делать нечего, но какие-то японцы продолжают ее поддерживать в живом состоянии (по мере эволюции D библиотеки постепенно протухают, если их не адаптировать к изменениям в языке). Японцы вообще активно на D что-то делают, похоже. Гугл иногда выбрасывает на их сайты и форумы о об этом языке.
Несмотря на наличие сборщика мусора и похожесть memory model на шарповскую, использовать нативный код, будь то WinAPI или сторонние сишные библиотеки, намного проще, т.к. можно спокойно передавать туда-сюда указатели на данные, не боясь, что сборщик их передвинет. Не нужны пиннинг и маршаллинг. Просто потому что сборщик не generational и данные в памяти вообще не двигает. Я в этом проекте задействовал libjpeg, подключить который оказалось не сложнее чем в проект на С/С++. Разве что lib файл пришлось сконвертить из COFF формата в OMF, иначе DMD его не понимал.
В результате получился бинарник меньше мегабайта, включающий в себя и DFL, и libjpeg, и многопоточный рантайм с GC, не требующий никаких dll-ок и фреймворков и мгновенно запускающийся. Это приятно.
Про многопоточность стоит рассказать отдельно. Предпочтительным подходом к ней в D считается Erlang-style message passing. Создаешь потоки и шлешь им сообщения. У каждого потока своя очередь сообщений. Сообщения можно матчить по типу:
receive - не ключевое слово, а обычная функция стандартной библиотеки, принимающая произвольное количество функций, описанных либо на месте лямбдами, либо отдельно, и по типу их входных аргументов она выбирает какую из них вызвать для очередного сообщения. Кстати, для описания функций есть множество способов:
и всякие их вариации с неуказанием типа или указанием auto вместо него. Некоторый вывод типов присутствует, так что полностью их не везде нужно указывать. Вот так все работает, например:
Разница между function и delegate предсказуемая: первое есть обычная C-style функция, без захвата окружения, второе - замыкание.
Так вот, посылать друг другу в сообщениях потоки могут не все подряд. В системе типов есть четкое разделение на immutable, mutable thread-local и mutable shared данные. Посылать можно immutable данные, ибо с ними никак накосячить нельзя, и можно посылать shared. По умолчанию все данные thread-local, при работе с ними компилятор волен делать более смелые оптимизации - не нужно заботиться о том, чтобы другие потоки видели изменения данных в том же порядке, например. С shared данными он работает более аккуратно, они как минимум volatile. Стандартные средства D не дают узнать, есть ли что-то в очереди сообщений другого потока и занят ли он чем-то. В таких условиях на чистом message passing'e я не знаю как реализовать load balancing по ядрам (как это сделано в эрланге, кстати?). Поэтому мне потребовалась общая приоритезированная очередь заданий, из которых рабочие потоки разбирали себе работу. Нужно, скажем, прочитать несколько картинок и сделать из них тамбнейлы - кладу в очередь соответствующие задания, посылаю рабочим потокам сообщения о том, что появилась работа. Если есть незанятые воркеры, они сразу начинают задания выполнять. Если нет - кто первый освободится, тот очередное задание и возьмет. Так нагрузка естественным образом распределяется по воркерам. Соответственно, очередь заданий - это один объект, к которому обращаются разные потоки. Для таких вещей в D все предусмотрено: ставишь слово synchronized прямо перед словом class, и все публичные методы автоматически становятся synchronized по локу внутри этого объекта, а все его данные автоматически становятся shared. Кроме того, synchronized можно ставить на отдельные методы или куски кода внутри методов, это как в C# сотоварищи.
Разделение в системе типов на shared данные и локальные - штука интересная и потенциально многообещающая (проще будет в будущем сделать правильный многопоточный GC и выделение памяти), но пока что плохо проработанная. Порой не хватает некоторого полиморфизма по этому признаку. Сейчас типы А и shared A считаются совершенно различными, и передать один вместо другого нельзя. Соответственно, если нужна операция, которая одинаково работает с А вне зависимости от его статуса, приходится либо дублировать функции, либо делать касты туда-сюда.
Такие вот впечатления. Приятный гибридный язык, сочетающий продвинутое ООП (я его не касался особо, там много можно рассказать), ФП, МП, хорошую сторону плюсовых шаблонов, и сохраняющий императивное программирование удобным. Из приятных мелочей: нужно было, например, в массиве-картинке в каждой четверке байтов обновить первые три по таблице. Вот как это выглядит:
В каком языке это делается проще и нагляднее?
Писать подобный софт под Haiku одно удовольствие, но к сожалению в Haiku у меня не работал кард-ридер и нужный вариант wifi, а туда-сюда перезагружаться было неохота, весь смысл терялся. Так что решение не прижилось. В этом году я подумал, что реализация такой смотрелки-ресайзилки - подходящая задача для изучения какого-нибудь языка. И поскольку мое нынешнее увлечение - язык D, решил сделать ее на нем. И сделал:

https://bitbucket.org/infognition/bsort/
Делал для себя, но если кому-то еще пригодится, буду рад. Из реализованных фич, которых мне так не хватало:
* Видеть текущую картинку в контексте соседних. Полезно, когда есть группы похожих фоток.
* Видеть в ряду тамбнейлов какие из фоток я уже сохранил. Помечаются тут зеленой рамкой.
* Если текущий файл сохраняется под именем drinking-my-juice-in-the-hood41.jpg, то для следующего файла автоматически будет предложено имя drinking-my-juice-in-the-hood42.jpg, которое я при желании могу поменять. А если не хочу менять имя, то сохранение очередного файла - одно нажатие клавиши.
* Зачем обычно нужен поворот на небольшой угол? Затем, что горизонт завален. Однако мне как-то не встречалось элементарное решение: выбрать две точки на горизонте, а дальше программа сама вычисляет нужный угол поворота и поворачивает. Сделал именно так: пара правых кликов на горизонте,
нажатие одной кнопки, и картинка повернута как надо:
Но вообще-то пост не об этом. Я хотел поделиться впечатлениями о D.
В целом, мне понравилось. По ощущениям, на D получается писать столь же коротко и просто, как на Руби, который в моем личном хит-параде был чемпионом по разумной лаконичности, но при этом иметь плюшки статической типизации - защиту от глупых ошибок и скорость. Система типов довольно интересная. Есть ООПшная база, очень похожая на C# (классы с reference семантикой, структуры с value семантикой, интерфейсы, наследование и т.д.) и параллельно есть умная статическая утиная типизация: на типы-параметры можно накладывать очень сложные условия и в зависимости от их выполнения выдавать разные результаты. Вплоть до проверок "если такой вот кусок кода имеет смысл (успешно типизируется), описать то-то, иначе сделать то-то или выдать такое-то подробное сообщение". Это активно используется в стандартной библиотеке, благодаря чему например выражение
iota(0, 1000000).map!(to!string).retro.take(50).retro[10].writeln;
аналогичное хаскелевскому
print . (!! 10) . reverse . take 50 . reverse $ map show [0..999999]
вычислится за О(1). Потому что функции map, take, retro и т.п. если видят, что входной тип умеет выдавать элементы по индексу, а не только по-очереди, возвращают тип, тоже предоставляющий такую возможность. Ну и большинство подобных алгоритмов там ленивые, пока мы тут конкретный элемент не попросили, никаких реальных вычислений не происходило.
Подобно тому, как в STL итераторы позволили по возможности разделить структуры данных и алгоритмы, в стандартной библиотеке D алгоритмы построены вокруг понятия range - это более продвинутые итераторы. Рекомендую почитать о них душеполезную статью. Большое подмножество языка доступно в компайл-тайме, можно читать файлы, делать вычисления, генерить код. Порадовало, как в сделана проверка "описывает ли тип бесконечную последовательность":
template isInfinite(R)
{
static if (isInputRange!R && __traits(compiles, { enum e = R.empty; }))
enum bool isInfinite = !R.empty;
else
enum bool isInfinite = false;
}
У любого range есть свойство empty, сообщающее, остались ли в последовательности еще элементы. Ключевое слово enum определяет константу, которая обязана быть вычислена в момент компиляции. Если свойство empty у R может быть вычислено при компиляции, значит это константа - либо всегда false, что значит, что данный range никогда не кончается, либо всегда true, что значит, что последовательность пуста.
В коде сказано, что если R - тип, описывающий последовательность (т.е. имеющий пару нужных методов, включая empty, что проверяется в isInputRange!R) и код "enum e = R.empty" компилируется, то последовательность бесконечна, если не пуста. Если же код "enum e = R.empty" не компилируется, то мы не можем статически гарантировать бесконечность, возвращаем false.
Благодаря возможности исполнять код в компайл-тайм, помимо обычный регулярных выражений в стандартной библиотеке есть также compile time regex'ы - там распознающий автомат генерится при компиляции программы, а не как обычно в рантайме. К сожалению, оба раза, что я пробовал их использовать, окончились неудачей - один раз компилятор разорвало на куски, другой раз регекс просто не срабатывал, в то время как его рантайм версия работала успешно.
Подобно ATS, у всякой функции в D есть два набора аргументов: статические (используемые при компиляции) и динамические (передающиеся в рантайме). В других языках набор статических параметров тоже бывает - в угловых или квадратных скобках - но там обычно это только типы, реже константы. В D скобки круглые, при описании функции просто может идти два набора аргументов в круглых скобках, а при вызове набор статических аргументов помечается восклицательным знаком. Если такой аргумент один, скобки можно опустить, так, "to!string" - это упрощенная запись "to!(string)" - функция to с переданным типом string. Так вот, в качестве статического параметра можно также передать кусок кода и получить специализированную им версию функции, получается что-то среднее между ФВП и макросом. Например, мне в этом проекте нужны две функции: повороты картинки на 90 градусов влево и вправо. Они очень похожи: обе получают данные исходной картинки, обе создают новую картинку одного и того же размера, обе заполняют в цикле новую картинку пикселями, взятыми из старой, и единственная разница между ними - вычисление индекса точки в старой картинке - откуда брать данные. В иных языках эту разницу можно выделить в функцию, сделать ФВП и надеяться, что компилятор ее проинлайнит. Здесь же я просто передаю короткий кусок кода в виде строки:
switch(angle & 3) {
case 0: turned = srcbmp; break;
case 1: turned = TurnBitmap!("x*w0 + w0-1-y")( srcbmp ); break;
case 2: turned = TurnAround( srcbmp ); break;
case 3: turned = TurnBitmap!("(h0-1-x)*w0 + y")( srcbmp ); break;
где
static Bitmap TurnBitmap(alias coord_calc)(Bitmap bmp)
{
...
dst[di + x] = src[mixin(coord_calc)];
...
}
Haters gonna hate, зато просто и эффективно.
Для GUI в D есть несколько библиотек разной степени готовности и протухшести, в том числе байндинги к GTK. Я взял DFL (D Forms Library) - обертка над WinAPI, очень похожая на Windows Forms, разве что без anchor'ов. К ней есть редактор форм Entice Designer, умеющий генерить и читать код, он же может использоваться в качестве редактора кода, но я предпочитаю VisualD. C DFL D еще больше похож на C#, который не требует установки фреймворка и запускается мгновенно. Автор библиотеки DFL забросил, видимо решив, что все работает и больше там делать нечего, но какие-то японцы продолжают ее поддерживать в живом состоянии (по мере эволюции D библиотеки постепенно протухают, если их не адаптировать к изменениям в языке). Японцы вообще активно на D что-то делают, похоже. Гугл иногда выбрасывает на их сайты и форумы о об этом языке.
Несмотря на наличие сборщика мусора и похожесть memory model на шарповскую, использовать нативный код, будь то WinAPI или сторонние сишные библиотеки, намного проще, т.к. можно спокойно передавать туда-сюда указатели на данные, не боясь, что сборщик их передвинет. Не нужны пиннинг и маршаллинг. Просто потому что сборщик не generational и данные в памяти вообще не двигает. Я в этом проекте задействовал libjpeg, подключить который оказалось не сложнее чем в проект на С/С++. Разве что lib файл пришлось сконвертить из COFF формата в OMF, иначе DMD его не понимал.
В результате получился бинарник меньше мегабайта, включающий в себя и DFL, и libjpeg, и многопоточный рантайм с GC, не требующий никаких dll-ок и фреймворков и мгновенно запускающийся. Это приятно.
Про многопоточность стоит рассказать отдельно. Предпочтительным подходом к ней в D считается Erlang-style message passing. Создаешь потоки и шлешь им сообщения. У каждого потока своя очередь сообщений. Сообщения можно матчить по типу:
receive(
(int x) { do something with int },
(Msg msg) { do something with msg },
...
&fun1,
&fun2,
(OwnerTerminated ot) { done = true;}
);
receive - не ключевое слово, а обычная функция стандартной библиотеки, принимающая произвольное количество функций, описанных либо на месте лямбдами, либо отдельно, и по типу их входных аргументов она выбирает какую из них вызвать для очередного сообщения. Кстати, для описания функций есть множество способов:
x => x*x
(int x) { return x*x; }
int function(int x) { return x*x; }
int delegate(int x) { return x*x; }
и всякие их вариации с неуказанием типа или указанием auto вместо него. Некоторый вывод типов присутствует, так что полностью их не везде нужно указывать. Вот так все работает, например:
auto hof(int function(int) f) { return f(3); }
writeln( hof(x => x*x) );
Разница между function и delegate предсказуемая: первое есть обычная C-style функция, без захвата окружения, второе - замыкание.
Так вот, посылать друг другу в сообщениях потоки могут не все подряд. В системе типов есть четкое разделение на immutable, mutable thread-local и mutable shared данные. Посылать можно immutable данные, ибо с ними никак накосячить нельзя, и можно посылать shared. По умолчанию все данные thread-local, при работе с ними компилятор волен делать более смелые оптимизации - не нужно заботиться о том, чтобы другие потоки видели изменения данных в том же порядке, например. С shared данными он работает более аккуратно, они как минимум volatile. Стандартные средства D не дают узнать, есть ли что-то в очереди сообщений другого потока и занят ли он чем-то. В таких условиях на чистом message passing'e я не знаю как реализовать load balancing по ядрам (как это сделано в эрланге, кстати?). Поэтому мне потребовалась общая приоритезированная очередь заданий, из которых рабочие потоки разбирали себе работу. Нужно, скажем, прочитать несколько картинок и сделать из них тамбнейлы - кладу в очередь соответствующие задания, посылаю рабочим потокам сообщения о том, что появилась работа. Если есть незанятые воркеры, они сразу начинают задания выполнять. Если нет - кто первый освободится, тот очередное задание и возьмет. Так нагрузка естественным образом распределяется по воркерам. Соответственно, очередь заданий - это один объект, к которому обращаются разные потоки. Для таких вещей в D все предусмотрено: ставишь слово synchronized прямо перед словом class, и все публичные методы автоматически становятся synchronized по локу внутри этого объекта, а все его данные автоматически становятся shared. Кроме того, synchronized можно ставить на отдельные методы или куски кода внутри методов, это как в C# сотоварищи.
Разделение в системе типов на shared данные и локальные - штука интересная и потенциально многообещающая (проще будет в будущем сделать правильный многопоточный GC и выделение памяти), но пока что плохо проработанная. Порой не хватает некоторого полиморфизма по этому признаку. Сейчас типы А и shared A считаются совершенно различными, и передать один вместо другого нельзя. Соответственно, если нужна операция, которая одинаково работает с А вне зависимости от его статуса, приходится либо дублировать функции, либо делать касты туда-сюда.
Такие вот впечатления. Приятный гибридный язык, сочетающий продвинутое ООП (я его не касался особо, там много можно рассказать), ФП, МП, хорошую сторону плюсовых шаблонов, и сохраняющий императивное программирование удобным. Из приятных мелочей: нужно было, например, в массиве-картинке в каждой четверке байтов обновить первые три по таблице. Вот как это выглядит:
foreach(i; iota(0, sz, 4))
foreach(ref x; data[i..i+3]) x = tab[x];
В каком языке это делается проще и нагляднее?
no subject
Date: 2012-10-02 04:08 pm (UTC)no subject
Date: 2012-10-02 04:54 pm (UTC)